How to display Markdown files from other sites: now with caching!
This post is part of a series: Displaying Markdown files from other sites
- How to display Markdown files from other sites in WordPress
- How to display Markdown files from other sites...this time in Blogofile
- How to display Markdown files from other sites: now with caching! (this post)
For quite some time now, the content of the project pages on my site (this one, for example) was coming directly from the respective Markdown readme file on Bitbucket (this one, for example).
I already wrote multiple times about how my approach how to get this to work - here, here and a bit here.
Until now, the code where all the magic happened looked like this:
<?php
include_once "markdown.php";
function GetMarkdown($url) {
$result = @file_get_contents($url);
if ($result === false)
{
return "Could not load $url";
}
else
{
return Markdown($result);
}
}
?>
It just loads the Markdown file from $url, converts the content to HTML and returns the HTML.
The problem is that it’s pulling the Markdown file directly from Bitbucket - on each request.
To make things worse, it’s not only the Markdown files: each readme contains at least one image (the project logo on the top), and some of the readmes have even more images - screenshots, for example.
All these images are directly coming from the Bitbucket repository as well…because in the Markdown files, I’m doing this:

In other words:
If you visited https://christianspecht.de/bitbucket-backup/, this happened:

Of course, all this together takes quite long:
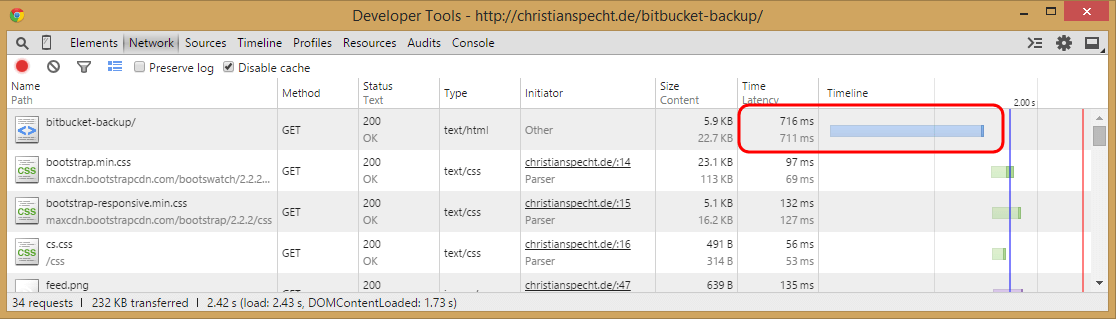
It could be worse, but >700ms isn’t quick either.
So I tried to cache everything on my web server to avoid the requests to Bitbucket.
Caching the Markdown/HTML file
I’m using PHP to load the Markdown files (because my webspace runs PHP anyway), but I have nearly no actual coding experience with it. So I looked around how others do caching in PHP, and found this tutorial.
Based on the code there, here is a new version of the GetMarkdown function, now with caching.
Note that this is not the complete version yet…the version shown here includes only the changes necessary to cache the Markdown file (but not the images):
function GetMarkdown($url, $title) {
// time (in seconds) how long a cached file is valid
$cachetime = 24 * 60 * 60;
// name of the cache file: /php/cache/project-name.html
$filename = str_replace(' ', '-', strtolower($title));
$cachefile = __DIR__ . '/cache/' . $filename . '.html';
// load content from cache file if it already exists
if (file_exists($cachefile) && time() - $cachetime < filemtime($cachefile)) {
$result = file_get_contents($cachefile);
return $result;
}
$result = @file_get_contents($url);
if ($result === false) {
return 'Could not load ' . $url;
}
else {
$html = Markdown($result);
$html = '<!-- cached ' . date('Y/m/d H:i:s') . ' -->' . PHP_EOL . $html;
$cached = fopen($cachefile, 'w');
fwrite($cached, $html);
fclose($cached);
return $html;
}
}
Quite simple, actually.
The function now expects a second parameter where I’m just passing the title of the calling page (“Bitbucket Backup”, for example). After removing blanks and converting to lowercase, the title becomes the name of the cached HTML file: bitbucket-backup.html
If there already is an existing cache file that’s not too old, I load the HTML from there.
If not, I make a request to the passed URL, get the Markdown file, convert it to HTML, save the HTML in the cache folder and return it to the caller.
That works well, but fixes only half of the loading time problem, because the images are still requested from Bitbucket.
Caching the images
I knew what I wanted to do:
- Search for
<img>tags in the HTML - Get the image URL out there
- Download the image from that URL on my server
- Replace the original URL in the HTML by the “local” one on my server
I just didn’t know how to do it in PHP…so after some more googling, I added more code between these two lines from the last listing:
$html = Markdown($result);
$html = '<!-- cached ' . date('Y/m/d H:i:s') . ' -->' . PHP_EOL . $html;
What I added was this:
// replace image URLs
$doc = new DOMDocument();
@$doc->loadHTML($html);
$images = $doc->getElementsByTagName('img');
foreach ($images as $image) {
$img = $image->getAttribute('src');
$img = DownloadImage($img, $filename);
$image->setAttribute('src', $img);
}
$html = preg_replace('/^<!DOCTYPE.+?>/', '', str_replace( array('<html>', '</html>', '<body>', '</body>'), array('', '', '', ''), $doc->saveHTML()));
The code gets the image URLs from the <img> tags and passes each one (together with the “blanks removed and lowercase” filename that was created for the cached HTML file) to the DownloadImage function:
function DownloadImage($url, $filename) {
$newfilename = $filename . '-' . basename($url);
$newfile = __DIR__ . '/cache/' . $newfilename;
$newurl = '/php/cache/' . $newfilename;
copy($url, $newfile);
return $newurl;
}
This function downloads the image to my server, and returns the “new” URL of the image, which the calling code then replaces in the <img> tag.
To stick with the example from above: the logo from the top of Bitbucket Backup’s readme file will be located here after being copied to my server.
(if you click on the link now and the image is not there, it’s probably because I updated my site shortly before, and updating always empties the cache folder)
There’s one special case that wouldn’t work with the DownloadImage function listed above:
When the page contains two images from different URLs with identical file names, my current naming pattern $filename.'-'.basename($url) would lead to identical file names on my server as well, so the second image would overwrite the first one.
But I will neclect this, because I’m the only one with full control over the readme files, so I’ll just make sure that none of them has identical image file names.
I think there’s only one thing that needs additional explanation: the $html = preg_replace(...) line.
It’s there because DOMDocument has this (IMO unnecessary) feature that loadHTML always inserts <!DOCTYPE ...>, <html> and <body> tags whenever the loaded document is lacking them.
If someone doesn’t want that (like me), there seem to be only two options. I can’t use the first/proper one (yet) because the PHP version on my server is too old, so I have no other choice than to use the ugly-looking preg_replace(...) line.
Conclusion
The current (as of the time of writing this post) version of the code is here. After pushing it to the live site, I opened the site with Chrome’s developer tools again.
The first load actually took some more time than before:
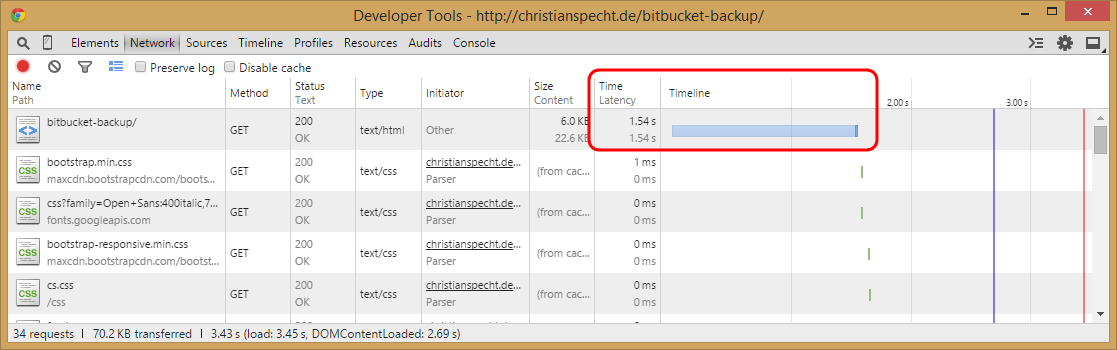
(before the change, it was about 700 ms)
But I expected that, because of course that time also includes copying the images from Bitbucket onto my server.
On the other hand, all subsequent requests were way faster:
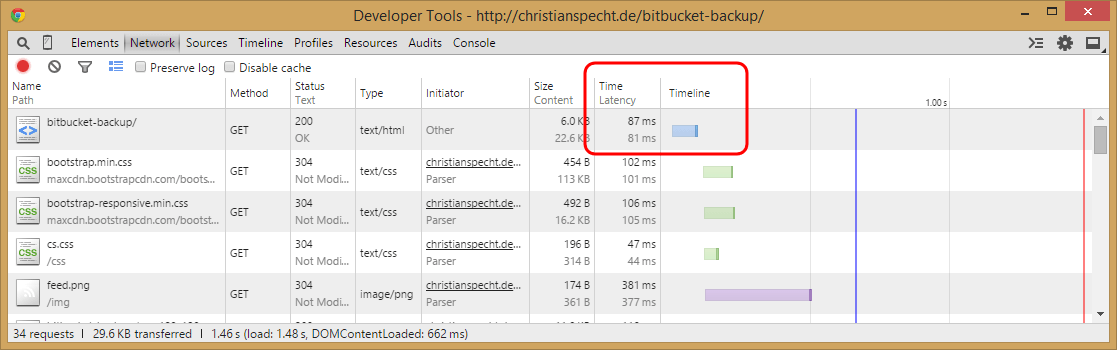
So the first visitor each day needs to wait a bit longer than before, but for everyone else the project pages are loading now nearly as fast as the other static pages (like this post).


{kind=link}